I was stunned when some of my BigQuery queries were taking a minute or so, instead of the usual few seconds. The culprit: Case insensitive searches. The good news: There are ways to make them way faster.
Note from the team: Stay tuned! Very soon BigQuery will turn this advice irrelevant.
Note 2: Good news! BigQuery has rendered this advice obsolete — LOWER() and UPPER() behave way faster now. Will I blog about this? Stay tuned!
The problem
Processing gigabytes of data with BigQuery should be super fast. For example the following query performs a case insensitive search over 5GB of text in 18 seconds:
#standardSQL
SELECT COUNT(*) c
FROM `bigquery-public-data.hacker_news.full`
WHERE LOWER(text) LIKE '%bigquery%' # 18s
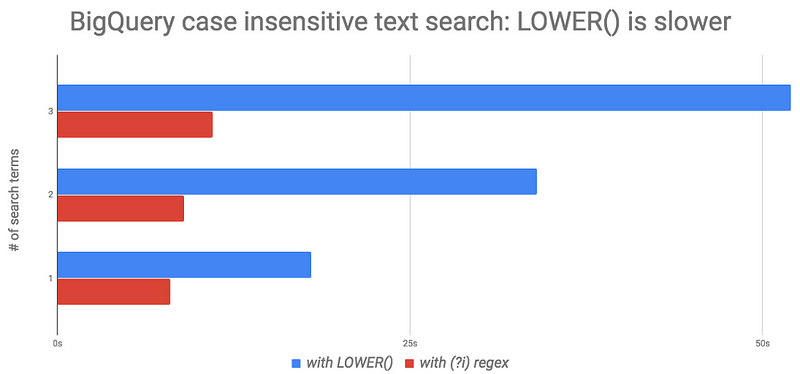
Usually BigQuery is faster than this, but the underlying problem becomes really apparent when adding new search terms. For example, when searching for 3 terms, a similar query takes almost a minute:
#standardSQL
SELECT COUNT(*) c
FROM `bigquery-public-data.hacker_news.full`
WHERE LOWER(text) LIKE '%bigquery%'
OR LOWER(text) LIKE '%big query%' # 34s#standardSQL
SELECT COUNT(*) c
FROM `bigquery-public-data.hacker_news.full`
WHERE LOWER(text) LIKE '%bigquery%'
OR LOWER(text) LIKE '%big query%'
OR LOWER(text) LIKE '%google cloud%' # 52s
How can I improve my query performance?
BigQuery performance tip: Avoid using LOWER()and UPPER()
LOWER() and UPPER() operations have a hard time when dealing with Unicode text: each character needs to be mapped individually and they can also be multi-byte.
There are 3 solutions that I covered on Stack Overflow:
Solution 1: Case insensitive regex
A faster alternative to
LOWER(): Use REGEX_MATCH() and add the case insensitive (?i) modifier to your regular expression:#standardSQL
SELECT COUNT(*) c
FROM `bigquery-public-data.hacker_news.full`
WHERE REGEXP_CONTAINS(text, '(?i)bigquery') # 7s# REGEXP_CONTAINS(text, '(?i)bigquery')
# OR REGEXP_CONTAINS(text, '(?i)big query') # 9s# REGEXP_CONTAINS(text, '(?i)bigquery')
# OR REGEXP_CONTAINS(text, '(?i)big query')
# OR REGEXP_CONTAINS(text, '(?i)google cloud') # 11s
Query execution time gets much better:
- 1 search term: 18s down to 8s
- 2 search terms: 34s down to 9s
- 3 search terms: 52s down to 11s.
Solution 2: Combine regexes
Why do 3 searches when a regular expression can combine them into 1?
#standardSQL SELECT COUNT(*) c FROM `bigquery-public-data.hacker_news.full` WHERE REGEXP_CONTAINS(text, '(?i)(bigquery|big query|google cloud)') # 7s
3 terms in 7s — nice.
Solution 3: Transform to bytes
This is uglier, but shows that
UPPER() and LOWER() perform way better when dealing with individual bytes — for equivalent results in these searches:#standardSQL SELECT COUNT(*) c FROM `bigquery-public-data.hacker_news.full` WHERE LOWER(CAST(text AS BYTES)) LIKE b'%bigquery%' OR LOWER(CAST(text AS BYTES)) LIKE b'%big query%' OR LOWER(CAST(text AS BYTES)) LIKE b'%google cloud%' # 7s
In closing
LOWER() is slower! Use the regex (?i) modifier instead.