BigQuery just announced the ability to cluster tables — which I’ll describe here. If you are looking for massive savings in costs and querying times, this post is for you.
Warning: This post plays with several terabytes of data. Set up your BigQuery cost controls, buckle up, keep calm, and query on.
Can you spot the huge difference between the query on the left and the one on the right?
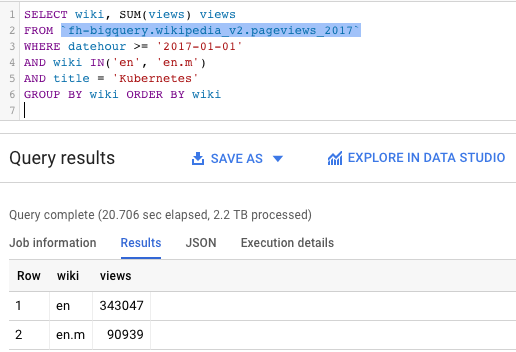
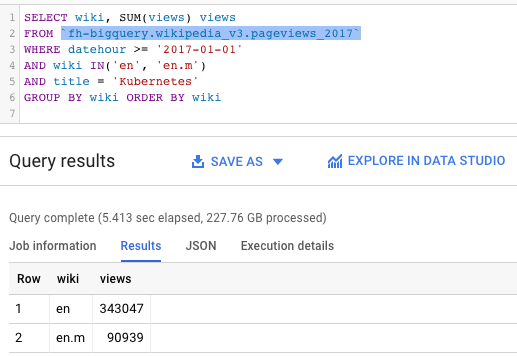
What can we see here:
- Kubernetes was a popular topic during 2017 in Wikipedia — with more than 400,000 views among the English Wikipedia sites.
- Kubernetes gets way less pageviews on the mobile Wikipedia site than on the traditional desktop one (90k vs 343k).
But what’s really interesting:
- The query on the left was able to process 2.2 TB in 20 seconds. Impressive, but costly.
- The query on the right went over a similar table — but it got the results in only 5.4 seconds, and for one tenth of the cost (227 GB).
What’s the secret?
Clustered tables!
Now you can tell BigQuery to store your data “sorted” by certain fields — and when your queries filter over these fields, BigQuery will be smart enough to only open the matching clusters. In other words, you’ll get faster and cheaper results.
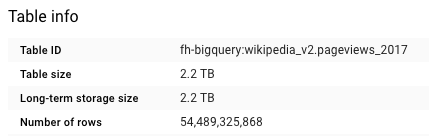
Previously I explained my lazy loading of Wikipedia views into partitioned yearly BigQuery tables. As a reminder, just for 2017 we will be querying more than 190 billion of pageviews, over 3,927 Wikipedia sites, covered by over 54 billion rows (2.2 TBs of data per year).
To move my existing data into a newly clustered table I can use some DDL:
CREATE TABLE `fh-bigquery.wikipedia_v3.pageviews_2017`
PARTITION BY DATE(datehour)
CLUSTER BY wiki, title
OPTIONS(
description="Wikipedia pageviews - partitioned by day, clustered by (wiki, title). Contact https://twitter.com/felipehoffa"
, require_partition_filter=true
)
AS SELECT * FROM `fh-bigquery.wikipedia_v2.pageviews_2017`
WHERE datehour > '1990-01-01' # nag
-- 4724.8s elapsed, 2.20 TB processed
Note these options:
- CLUSTER BY wiki, title: Whenever people query using the
wikicolumn, BigQuery will optimize these queries. These queries will be optimized even further if the user also filters bytitle. If the user only filters bytitle, clustering won’t work, as the order is important (think boxes inside boxes). - require_partition_filter=true: This option reminds my users to always add a date filtering clause to their queries. That’s how I remind them that their queries could be cheaper if they only query through a fraction of the year.
- 4724.8s elapsed, 2.20 TB processed: It took a while to re-materialize and cluster 2.2 TB of data — but the future savings in querying makes up for it. Note that you could run the same operation for free with a
bq export/loadcombination — but I like the flexibility that DDL supports. Within theSELECT * FROMI could have filtered and transformed my data, or added more columns just for clustering purposes.
Better clustered: Let’s test some queries
SELECT * LIMIT 1
SELECT * LIMIT 1 is a known BigQuery anti-pattern. You get charged for a full table scan, while you could have received the same results for free with a table preview. Let’s try it on our v2 table:SELECT *
FROM `fh-bigquery.wikipedia_v2.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
LIMIT 1
1.7s elapsed, 180 GB processed
Ouch. 180 GB processed — but at least the date partitioning to cover only June worked. But the same in
v3, our clustered table:SELECT *
FROM `fh-bigquery.wikipedia_v3.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
LIMIT 1
1.8s elapsed, 112 MB processed
Yes!!! With a clustered table we can now do a SELECT * LIMIT 1, and it only scanned 0.06% of the data (in this case).
Base query: Barcelona, English, 180->10GB
SELECT wiki, SUM(views) views
FROM `fh-bigquery.wikipedia_v2.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
AND wiki LIKE 'en'
AND title = 'Barcelona'
GROUP BY wiki ORDER BY wiki
18.1s elapsed, 180 GB processed
Any query similar to this will incur costs of 180 GB on our
v2 table. Meanwhile in v3:SELECT wiki, SUM(views) views
FROM `fh-bigquery.wikipedia_v3.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
AND wiki LIKE 'en'
AND title = 'Barcelona'
GROUP BY wiki ORDER BY wiki
3.5s elapsed, 10.3 GB processed
On a clustered table we get the results on 1/6th of the time, for 5% of the costs.
Don’t forget the clusters order
SELECT wiki, SUM(views) views
FROM `fh-bigquery.wikipedia_v3.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
-- AND wiki = 'en'
AND title = 'Barcelona'
GROUP BY wiki ORDER BY wiki
3.7s elapsed, 114 GB processed
If I don’t make use of my of my clustering strategy (in this case: filtering by which of the multiples wikis first), then I won’t get all the possible efficiencies — but it’s still better than before.
Smaller clusters, less data
The English Wikipedia has way more data than the Albanian one. Check how the query behaves when we look only at that one:
SELECT wiki, SUM(views) views
FROM `fh-bigquery.wikipedia_v3.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
AND wiki = 'sq'
AND title = 'Barcelona'
GROUP BY wiki ORDER BY wiki
2.6s elapsed, 3.83 GB
Clusters can LIKE and REGEX
Let’s query for all the wikis that start with
r, and for the titles that match Bar.*na:SELECT wiki, SUM(views) views
FROM `fh-bigquery.wikipedia_v3.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
AND wiki LIKE 'r%'
AND REGEXP_CONTAINS(title, '^Bar.*na')
GROUP BY wiki ORDER BY wiki
4.8s elapsed, 14.3 GB processed
That’s nice behavior —clusters can work with
LIKE and REGEX expressions, but only when looking for prefixes.
If I look for suffixes instead:
SELECT wiki, SUM(views) views
FROM `fh-bigquery.wikipedia_v3.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
AND wiki LIKE '%m'
AND REGEXP_CONTAINS(title, '.*celona')
GROUP BY wiki ORDER BY wiki
(5.1s elapsed, 180 GB processed
That takes us back to 180 GB — this query is not using clusters at all.
JOINs and GROUP BYs
This query will scan all data within the time range, regardless of what table I use:
SELECT wiki, title, SUM(views) views
FROM `fh-bigquery.wikipedia_v2.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
GROUP BY wiki, title
ORDER BY views DESC
LIMIT 10
64.8s elapsed, 180 GB processed
That’s a pretty impressive query — we are grouping thru 185 million combinations of (wiki, title) and picking the top 10. Not a simple task for most databases, but here it looks like it was. Can clustered tables improve on this?
SELECT wiki, title, SUM(views) views
FROM `fh-bigquery.wikipedia_v3.pageviews_2017`
WHERE DATE(datehour) BETWEEN '2017-06-01' AND '2017-06-30'
GROUP BY wiki, title
ORDER BY views DESC
LIMIT 10
22.1 elapsed, 180 GB processed
As you can see here, with
v3 the query took one third of the time: As the data is clustered, way less shuffling is needed to group all combinations before ranking them.FAQ
My data can’t be date partitioned, how do I use clustering?
Two alternatives:
1. Use ingestion time partitioned table with clustering on the fields of your interest. This is the preferred mechanism if you have > ~10GB of data per day.
2. If you have smaller amounts of data per day, use a column partitioned table with clustering, partitioned on a “fake” date optional column. Just use the value NULL for it (or leave it unspecified, and BigQuery will assume it is NULL). Specify the clustering columns of interest.
1. Use ingestion time partitioned table with clustering on the fields of your interest. This is the preferred mechanism if you have > ~10GB of data per day.
2. If you have smaller amounts of data per day, use a column partitioned table with clustering, partitioned on a “fake” date optional column. Just use the value NULL for it (or leave it unspecified, and BigQuery will assume it is NULL). Specify the clustering columns of interest.
What we learned today
- Cluster your tables — it’s free and it can optimize many of your queries.
- The main cost of clustering is longer load times, but it’s worth it.
- Make a sensible decision of what columns you’ll cluster by and the order of them. Think about how people will query your tables.
- Clustered tables are in beta — check the docs for limitations and updates.
- Engineers tip: I’ve heard that for now it’s better if you load data into your clustered tables once per day. On that tip, I’ll keep loading the hourly updates to
v2, and insert the results intov3once the day is over. From the docs: “Over time, as more and more operations modify a table, the degree to which the data is sorted begins to weaken, and the table becomes partially sorted”.
Next steps
Clustered tables in only one of many new BigQuery capabilities: Check out GIS support (geographical), and BQML capabilities (machine learning within BigQuery).
Want more stories? Check my Medium, follow me on twitter, and subscribe to reddit.com/r/bigquery. And try BigQuery — every month you get a full terabyte of analysis for free.