Migration to Google Cloud Platform (GCP)

Our aim was to choose a right cloud platform that would help us build, test, and deploy applications quickly in a scalable, reliable cloud environment. Although all large scale Cloud Platforms may seem similar in many ways, there are several fundamental differences in large scale cloud platforms.
We’re going to split this blog post into 2 parts:
- Why we chose to move to GCP
- Migrating to GCP without any downtime
Proof of ConceptWe started the process with a POC in which we considered existing running infra compatibilities with services offered by the Google Cloud Platform and also planned for elements in our future roadmap.
Key areas covered in POC:
⊹ Load Balancer
⊹ Compute Engine
⊹ Networking and Firewalls
⊹ Security
⊹ Cloud Resource Accessibility
⊹ Big Data
⊹ Billing
⊹ Load Balancer
⊹ Compute Engine
⊹ Networking and Firewalls
⊹ Security
⊹ Cloud Resource Accessibility
⊹ Big Data
⊹ Billing
The POC included testing and verifying for VMs/Network/Load Balancer Throughput, Stability, Scalability, Security, Monitoring, Billing, Big Data and ML services. We took the big decision in June 2017 to migrate the entire infrastructure stack to the Google Cloud Platform.
We wanted to opt for a cloud platform that cloud take care of the myriad challenges we were facing:
⊹ Load Balancer:
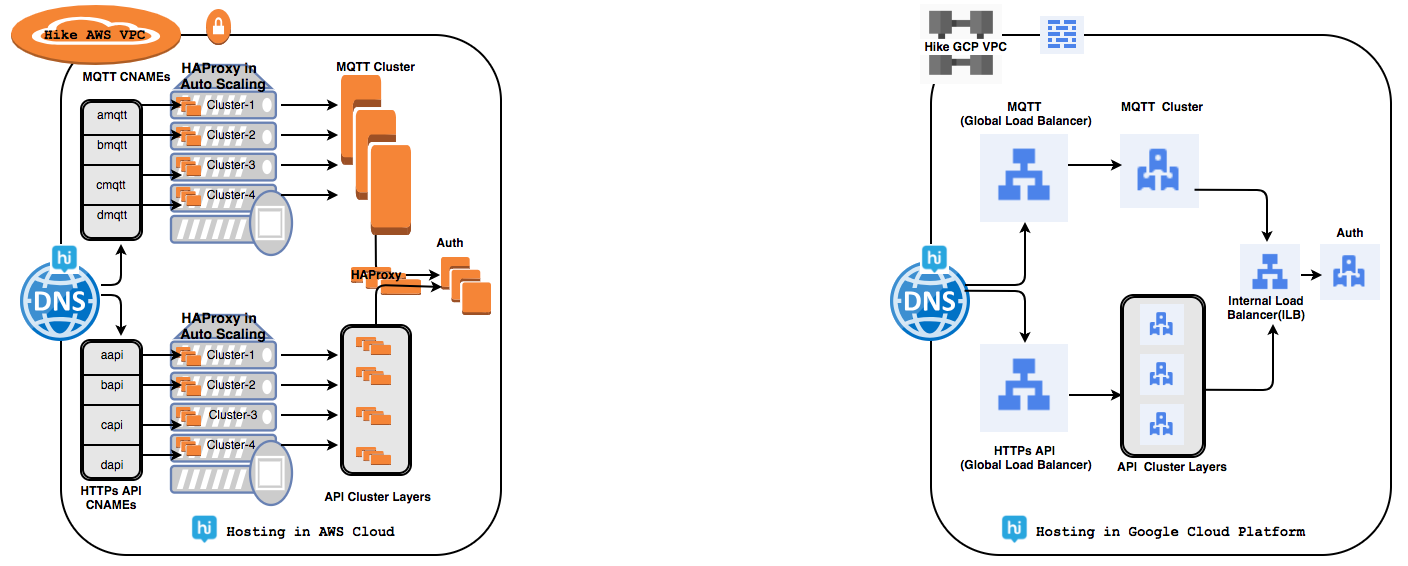
We had faced many challenges while managing HAProxy inhouse clusters to handle a few tens of millions of daily active user base connections. Global Load Balancer (GLB) solved our many challenges.
We had faced many challenges while managing HAProxy inhouse clusters to handle a few tens of millions of daily active user base connections. Global Load Balancer (GLB) solved our many challenges.

Using GCP’s global load balancing, a single anycast IP can forward up to 1 million requests per second to various GCP back-ends such as Managed Instance Groups(MIG) and it didn’t require any pre-warming. Our overall response time improved to 1.7–2x as GLB’s utilizes a pool implementation that allows for the traffic to be distributed to multiple origins.
⊹ Compute Engine:
There was as such no big challenges in compute engines but we needed a performant platform at a viable cost. Google cloud VMs overall throughput has improved to 1.3–1.5x and thereby helping us to reduce the total number of running VM instances.
There was as such no big challenges in compute engines but we needed a performant platform at a viable cost. Google cloud VMs overall throughput has improved to 1.3–1.5x and thereby helping us to reduce the total number of running VM instances.
Redis benchmark tests were run across a cluster of 6 instances (8 core, 30GB each). From the results below, we concluded that GCP provides up to 48% better performance (on average) for most REDIS operations, and up to 77% better performance for specific REDIS operations.
redis-benchmark -h <hostname> -p 6379 -d 2048 -r 15 -q -n 10000000 -c 100
Google Compute Engine (GCE) services added more values in our infrastructure management using:
● Managed Instance Group (MIG): MIGs help us to keep running our app services in a robust environment with multi-zone features instead of provisioning resource per zone. MIG automatically identifies and recreates unhealthy instances in a group to ensure that all of the instances are running optimally.
● Live Migration: Live migration helps us keep our VM instances running even when a host system down event occurs, like a software or hardware update. With our previous cloud partner, we used to get a schedule event notification for maintenance that forced us to stop and start VM to move on healthy VM.
● Custom VMs: In GCP’s we can create custom VM’s with the optimal amount of CPU and memory for workloads needed.
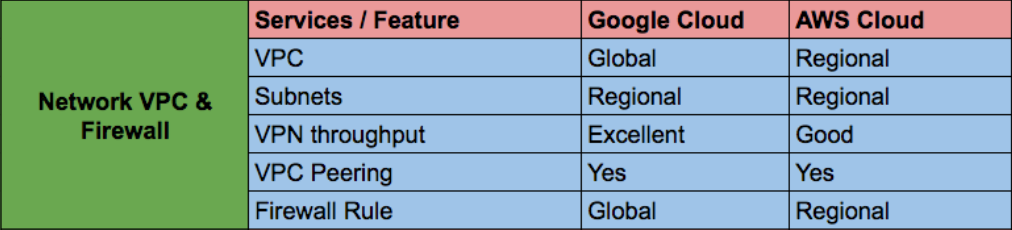
⊹ Networking and Firewalls:Manageability of multiple networks and firewall rules is not easy as this can lead to risk. GCP’s network VPC is global by default and enables inter-region communication with no extra setup and no change in network throughput. Firewall rules gives us flexibility within VPC for across projects using tag rule name.
For low-latency network and higher throughput we had to choose expensive 10G-capable instances and enabled enhanced networking on those instances.
⊹ Security:Security is most important aspect for any cloud provider. In our past experiences, security was either not available or optional to choose for most of services.
Google Cloud services are encrypted by default. GCP uses several layers of encryption to protect data. Using multiple layers of encryption adds redundant data protection and allows us to select the optimal approach based on application requirements. like Identity-Aware Proxy and encryption at rest by default.
GCP’s handling of the recent catastrophic speculative execution vulnerabilities in the vast majority of modern CPUs (Meltdown, Spectre) is also instructive. Google developed a novel binary modification technique called Retpoline which sidesteps the problem and transparently applied the change across running infrastructure without users noticing.
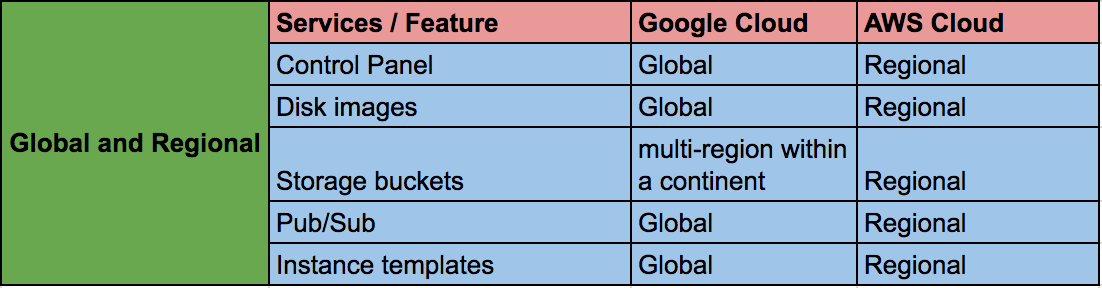
⊹ Cloud Resource Accessibility:GCP’s resource accessibility differs from other cloud providers as in GCP’s most resources, including the control panel, are either zonal or regional. We had to manage multiple VPCs for separate projects from separate accounts which needed VPC peering or VPN connection for private connectivity. We also had to maintain image replica in separate account too.
In Google Cloud most resources are either Global or Regional. This includes things like the control panel (where we can see all of our project’s VMs on a single screen), disk images, storage buckets (multi-region within a continent), VPC(but individual subnets are regional), Global Load Balancing, Pub/Sub etc.
⊹ Big Data:We went from a monolithic, hard to manage analytics setup to a full managed setup with BQ and resulted in 3 key areas of improvement:
● upto 50x Faster Querying
● Fully Managed & Autoscaled Data Systems
● Data Processing down to 15m from hours before.
● Fully Managed & Autoscaled Data Systems
● Data Processing down to 15m from hours before.
⊹ Billing:It was tough to compare different cloud providers since many services were not similar or comparable, were different for different use cases, and dependent on unique use cases.
GCP’s advantages were:
● Sustained Use Discounts: Sustained These are applied on incremental VM use when they reach certain usage thresholds. We can automatically get up to 30%-off for workloads that run for a significant portion of the billing month.
● Per Minute Billing: GCE has a minimum slab of 10 minutes after billing per minute of actual VM usage. This provides a significant cost reduction given we don’t have to pay for the entire hour even when an instance runs for less than an hour.
● Superior Hardware, Fewer Instances: For almost all tiers and applications we found that it was possible to run the same workload at the same performance with fewer equivalent instances in GCP.
● Commitment Vs Reservation: One additional factor is GCP’s take on VM instance pricing. With AWS, the main way to cut VM instance costs is buying reserved instances for 1–3 years terms. If workload required change in VM configuration or we didn’t need the instance, we had to sell the instance on the Reserved Instance Marketplace with cheaper rate. With GCP’s, “Committed Use Discount” which is done for CPU and Memory reservation, it does not matter what kind of VM instances we are running.
ReplyDeleteGood Article Keep on sharing
Google Cloud Platform Training
GCP Online Training
Google Cloud Platform Training In Hyderabad
nice information thanks for sharing.......................!
ReplyDeletegoogle cloud data engineer certification